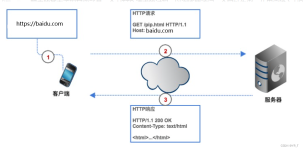
早在1989年,网络发明人蒂姆·伯纳斯 - 李(Tim Berners-Lee)就提出了网站的三大支柱:1)URL ,跟踪Web文档的地址系统2)HTTP,一个传输协议,以便在给定URL时查找文档3)HTML, 允许嵌入超链接的文档格式Web的最初...
”爬虫 python“ 的搜索结果
以下是爬虫Python基础知识的一些要点: 网络请求库:Python中常用的网络请求库有urllib和requests,它们可以发送HTTP请求并获取响应内容。 解析库:解析库用于解析HTML或XML等页面文档,提取出所需的数据。Python...
python爬虫python爬虫
1、python爬取企查查公司信息 2、添加应对反爬的设置 3、开箱即用,有示例数据文件 4、windows版本 5、需要登录或者人工验证 6、采用selenium模块+chromedriver驱动
利用Python来实现的爬虫,高效且可靠。
百度图片爬虫,可以利用该python程序对百度图片进行爬取。运行文件,在终端输入需要搜索的图片内容,即可爬取图片,自动生成文件夹将爬取的图片保存,文档内部代码简单易懂
爬虫python入门
超级简单的Python爬虫入门教程(非常详细),通俗易懂,看一遍就会了
爬虫的全称为网络爬虫,简称爬虫,别名有网络机器人,网络蜘蛛等等。网络爬虫是一种自动获取网页内容的程序,为搜索引擎提供了重要的数据支撑。搜索引擎通过网络爬虫技术,将互联网中丰富的网页信息保存到本地,形成...
书籍资源
网络爬虫-Python和数据分析,非常好的python 学习书籍
爬虫python入门
爬虫python入门
如果你仔细观察,就不难发现,懂爬虫、学习爬虫的人越来越多,一方面,互联网可以获取的数据越来越多,另一方面,像 Python这样的编程语言提供越来越多的优秀工具,让爬虫变得简单、容易上手。爬取知乎优质答案,为...
Python爬虫利器二之Beautiful Soup的用法
爬虫python入门 爬虫python入门实战源码 爬虫python入门实战源码 爬虫python入门实战源码
爬虫python入门
爬虫python入门

爬虫python,巨细!Python爬虫详解

爬虫python入门
py爬虫Python爬虫Scrapy培训源码提取方式是百度网盘分享地址
讲诉python爬虫的20个案例 。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
可从500px、Flickr、iStock、shutterstock等图片网站上批量爬取图片。input_filename为一个txt文件,txt文件中可有多行网址,每行是每页的网址。output_folder是爬取后的输出文件夹。
爬虫python入门,模拟登陆,获取人名,微博信息等,多线程模拟登陆 多线程,广度优先 正则表达式提取信息 获得的信息插入数据库 需要在本地搭建一个数据库和表, 用python写出来的程序相比其他语言简单的多,用到的...
81个Python爬虫源代码
标签: 爬虫
81个Python爬虫源代码,内容包含新闻、视频、中介、招聘、图片资源等网站的爬虫资源
推荐文章
- 大数据和云计算哪个更简单,易学,前景比较好?_大数据和云计算哪个好-程序员宅基地
- python操作剪贴板错误提示:pywintypes.error: (1418, 'GetClipboardData',线程没有打开的剪贴板)...-程序员宅基地
- IOS知识点大集合_ios /xmlib.framework/headers/xmmanager.h:66:32: ex-程序员宅基地
- Android Studio —— 界面切换_android studio 左右滑动切换页面-程序员宅基地
- 数据结构(3):java使用数组模拟堆栈-程序员宅基地
- Understand_6.5.1175::New Project Wizard_understand 6.5.1176-程序员宅基地
- 从零开始带你成为MySQL实战优化高手学习笔记(二) Innodb中Buffer Pool的相关知识_mysql_global_status_innodb_buffer_pool_reads-程序员宅基地
- 美化上传文件框(上传图片框)_文件上传框很丑-程序员宅基地
- js简单表格操作_"var str = '<table border=\"5px\"><tr><td>序号</td><-程序员宅基地
- Power BI销售数据分析_powerbi汇总销售人员业绩包括无销售记录的人-程序员宅基地